
Design Distributed Ledger System
When, why, and where to use this?


I’ve been dealing with ledgers in the past 5 years often, from managing sales records, to managing inventories. In this post, we discuss why Ledger is interesting for you to consider for your next highly reliable application.
Introduction
Ledger is a common concept for bookkeeping of immutable data in financial organizations or supply-chains.
Historically, Ledger refers to a book to keep track of accounting transactions.
For each account in the ledger, we have a reliable view of what is its current state (reliability), and how it gets here (traceability).
Imagine you are maintaining a ledger for your family’s piggy bank. You start the ledger with an initial amount of deposit as the very first entry. And then each time that you put money into the piggy bank, or withdraw money from it, you will add a new entry.
As a merchant, you have to do an inventory - knowing what you own. Imagine that you have never had an account before, the first thing you do when you are opening the book is taking an inventory and that becomes your capital. That is all your wealth. — Planet Money - Summer School 3: Accounting and The Last Supper
Before we dive into how to build the ledger, let’s take a look at what is the fundamental problem that it solves.
What Problem Does Ledger Solve
What is the main problem that the ledger solves that other systems may not? Let’s take a look at some of the key features that we would like to achieve for bookkeeping purposes.
Feature I: For any given account, we would like to retrieve the latest value for the account.
Feature II: For any transaction taking place in the system, we would like to see the accounts impacted. For example, if we have a transfer request between two accounts, I would like to be able to link the deposit in one account with the credit to the other account.
Feature III: For a given account in the system, we would like to see all the historical changes.
Here we will dive into a few different ways that we can design the system to support these features.
Design 1: Account Table + Log Table
The most straight-forward design idea is to use a combination of a current-state table and a log table.
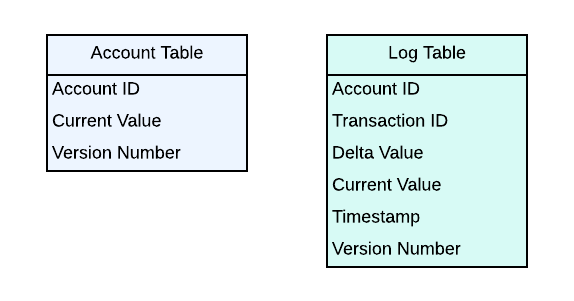
For feature I, it is easily achievable with any SQL table or any key-value store. Let’s call it Account Table, which can contain the following columns:
Account ID - an unique identifier for the account
Current Value - the current value for the account
Version Number - the version number for handling race conditions on writes
For Feature II and Feature III, we could achieve that by logging. For example, we can have a Log Table, with the following schema:
Account ID - an unique identifier for the account
Transaction ID - an unique identifier for the transaction
Delta Value - the delta amount that is changed
Current Value - the new value after the transaction is completed
Timestamp - the timestamp for when the transaction
Version Number - the version number for handling race conditions on writes
However, there are a few major problems with this approach.
Problem 1 - Data Consistency
Since updating the entries in the Account Table and generating logs are separate asynchronous operations, there is no way to guarantee that they can be in one atomic transaction.
Assuming we have a logging service that supports 99.99% reliability. Then it can imply that every 1 million updates we can miss 100 records in the log table.
Problem 2 - Query Complexity
Most log tables are designed to keep track of history for a given period of time. Therefore, most logs are partitioned by date time.
In order to find out all the accounts impacted by a transaction, it requires a full-table scan. Similarly, In order to have a holistic picture of what are all the changes to an account, it would also require a full-table scan.
Design 2: Both Table In The Same Database
In Design 1 above, we assume that we are using a service log. However, logs are designed for investigating issues and have their shortcomings.
How about we implement the Log Table differently using the same transitional database as the Account Table? For example, if we store the Account Table in MySQL, we can do the same for the Log Table. Let’s see how this can address the problems previously.
Solution For Problem 1 - Data Consistency
Most modern Database solutions, regardless whether SQL, or no-SQL, support transactions across multiple tables. Examples:
This solves our problem with consistency. We can update both the Account Table and Log Table at the same time in one atomic mutation.
Solution For Problem 2 - Query Complexity
Previously, it was computationally expensive to search for all the impacted accounts by a transaction (Feature II) and expensive to load all historical mutations for a given account (Feature III).
We can now solve them easily by having database indexes on both Transaction ID and Account ID columns on the Log Table.
Design 3: One Unified Table
If we inspect the columns for the Account Table and the Log Table, it is not hard to see that there are a lot of duplicates. As a matter of fact, the Log Table should have contained all the information on the Account Table.
Would it be possible to drop the Account Table and rely on the Log Table completely?
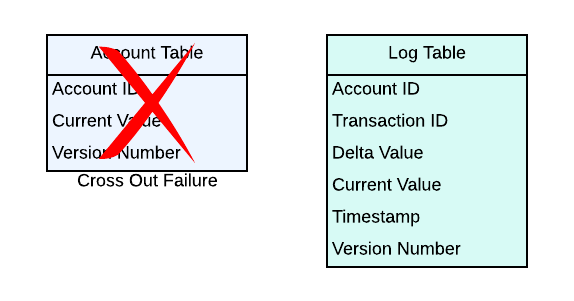
Previously, the complexity for retrieving the most recent value for a given account was O(1). The only outstanding question is: if we only have the Log Table, how much overhead would we introduce to accessing the most recent value for a given account?
This is dependent on the database.
For DynamoDB, we can set the Account ID as partition key and Version Number as the range key. Then the record is ordered, making it fast to retrieve the lastest value.
In MySQL, B-Tree is often used for indexing to support ordering. If we have a composite key defined for the Account ID and the Version Number columns, it will also make it relatively quick to retrieve the latest value.
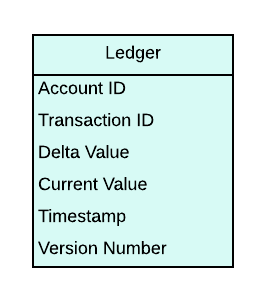
Indeed, we don’t have to maintain a separate Account Table!
With only one table left for us to maintain for storing both state and logs, we often refer to this as the Ledger.
Tradeoffs
Just as Thomas Sowell once said: There Are No Solutions, Only Trade-offs. This is true in any system design. What are the tradeoffs for ledger compared to only storing a simple table for the most recent ?
Here are a few:
Ledger requires storing more data since it captures all the historical changes, making it more challenging to scale.
We can tweak our design to make it more efficient to load the most recent, but there are still unavoidable some overhead
It is more complicated to understand, explain to others, and harder to implement & maintain
Then the question becomes: is keeping track of all the transaction history reliably really that important to your application?
If the answer is yes, then you should consider adopting the ledger. Otherwise, maybe you should not.
Where Ledger Is Valuable
With the trade offs in mind, what are some example applications to consider ledger?
It could be a banking application to keep track of the balance of the accounts, or an ecommerce system to keep track of the sales record or inventory, etc.
In general, anything related to purchasing, inventory, or money, are good candidates to consider the Ledger system.
Conclusion
Ledger is an old concept that has existed for hundreds and thousands of years. But in computer systems, ledger is a simple database schema design idea making it easy to keep track of all the histories reliably.
Hope this post helps you understand this concept better and help you with your decision whether to adopt this.
That’s it about Ledger. Thanks for reading!