
Versioned Data Management System Design
Introducing a Reliable Way to Manage Your Critical Data


Introduction
Previously, I introduced a distributed ledger system. From a technical level, I explained how to build a data store that supports version history consistently. Expanding on this, this post draws parallels to Git and introduces a data management workflow accordingly.
Version History for Data
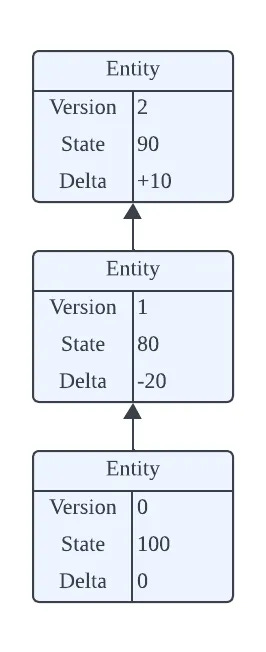
As discussed in the distributed ledger system, we maintain a linear history for each piece of the data. We can look up the current state by retrieving the entry with the most recent version number. Additionally, with a given version number, it allows us to access the earlier historical state.
To know the delta for a specific version, there are two approaches: 1) comparing or subtracting the current state from the previous state, or 2) storing the delta alongside with the data entry. The diagram below illustrates the latter method.
Numerous types of data can benefit from maintaining a comprehensive record of all the historical mutations. Examples include financial account data, supply chain inventory data, and critical configuration data.
As a concrete example, consider a bank checking account. Beyond simply tracking the current balance, it is crucial to have access to a detailed history of all transactions.
Not hard to see, this system closely resembles version control systems for source code. Both systems maintain an immutable changelog, with a key distinctions: in source control, we keep track of the delta only, whereas in the versioned data system, it is more important to keep track of the current state. Storing delta is optional and can easily be derived by comparing or subtracting the current state from the previous state.
In addition, the diagram above illustrates the “state” being an integer number. But in practice, this can be the value of any arbitrary key-value store.
Request Management Workflow
In most scenarios, the ability to track historical mutations is typically sufficient. Nevertheless, in some situations, ensuring the safety of mutations is equally crucial. Here are some examples we encountered:
Permissions: The initiator of a mutation may not necessarily be the authorized person to commit the change.
Simulation & Validation: Additional validation or simulations are necessary before committing the changes.
Future Plans: We would like to prepare for the change and commit it at a later time.
For any of these use cases, it is beneficial to have the mutation in staging mode.
As illustrated below, each proposed mutation is assigned a temporary version number. We can run a simulation to validate the legitimacy of the mutation. Following successful simulation and validation, the proposed mutation is then incorporated into the main history ledger with a new permanent version number.
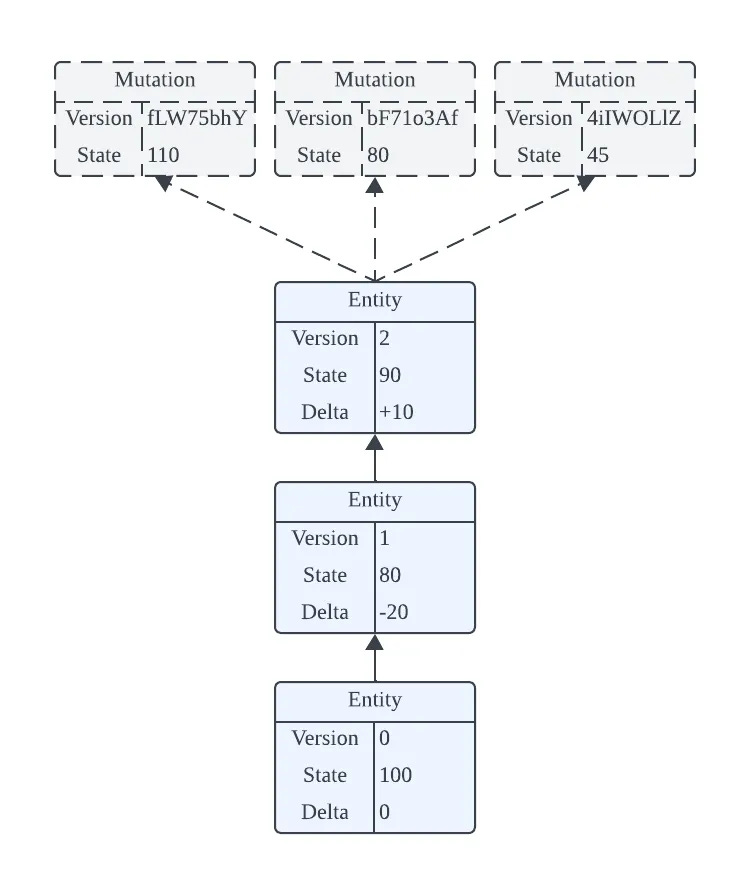
Let’s refer to this process as request management workflow, which is similar to the code review process. The simulation and validations conducted on a staging version of the mutation are akin to the unit tests run as part of the code review.
Database Design
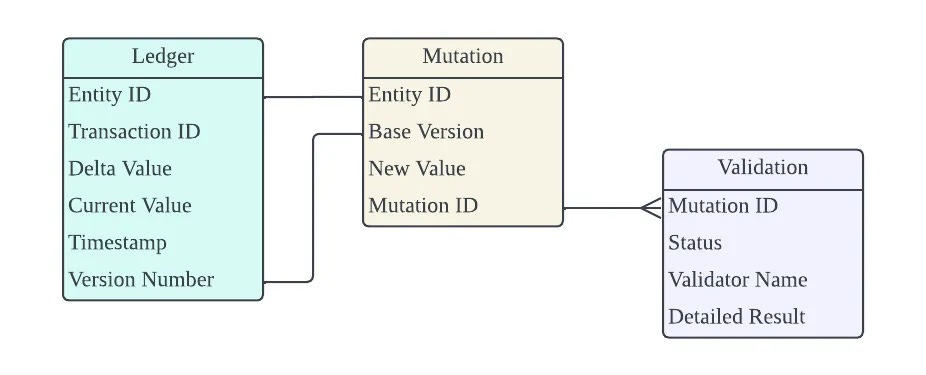
In this system, we require at least three primary tables:
A Ledger Table to maintains all the versions of the entity, with the primary key being the composite key of Entity ID and Version Number. More details can be found in the earlier post.
A Mutation Table is responsible for tracking all pending mutations that are yet to be applied to the Ledger table.
A Validation Table keeps a cored of validation results for each mutation. The status of a validation can be either pending, succeeded, or failed. The “Validator Name” column is to distinguish multiple validations for a single mutation. Lastly, the “Detailed Result” column stores a detailed message indicating the success or failure reasons of the validations.
API Design
To support the request management workflow, the following are two key APIs.
(1) Submit Mutation API
In this API, given the entity id, base version, and the new value, the response includes a unique mutation ID for the submitted mutation.
service VersionedDataService {
rpc SubmitMutation (MutationRequest) returns (MutationResponse);
}
message MutationRequest {
string entity_id = 1;
int32 base_version = 2;
string new_value = 3;
}
message MutationResponse {
string mutation_id = 1;
}(2) Commit Mutation
In this API, given a mutation ID, the changes are applied to the Ledger once all validations are successful.
service VersionedDataService {
rpc CommitMutation (CommitMutationRequest) returns (CommitMutationResponse);
}
message CommitMutationRequest {
string mutation_id = 1;
}
message CommitMutationResponse {
string message = 1;
}Other less essential APIs are omitted from this post.
Conclusion
Typically, it is not straightforward to know: what data was changed, why they were changed, by whom, and when. The tracking are usually added as an afterthought as logs. With this framework, we established a reliable and consistent way for clear traceability.
In the meantime, most of the mutations are done ad hoc without validations. This framework enhanced the reliability by proactively surfacing the impact of the changes and preventing mutations that might introduce regression.
And that’s it for today. Thanks for reading!